Having picked the name regulate.tech for this space, I should probably kick things off by setting out what I mean by “regulate” and “tech”. These definitions reflect the way my mind works and will shape how I will write about this subject. Other people will have their own way of structuring this debate and I will look at any alternative framing with interest.
Let’s start with the object of the exercise “tech”. Here, I have in mind what we used to call ICT, or “Information and Communications Technology” in the UK.
Information and communications technology (ICT) is an extensional term for information technology (IT) that stresses the role of unified communications[1] and the integration of telecommunications (telephone lines and wireless signals) and computers, as well as necessary enterprise software, middleware, storage, and audiovisual systems, that enable users to access, store, transmit, and manipulate information.[2]
https://en.wikipedia.org/wiki/Information_and_communications_technology
This definition includes what people mean today when they talk about “big tech” including both entities that provide software-based services and those that deliver the hardware and connections which allow people to use online services.
Most people think of the internet when talking about the tech sector but this is not a necessary component when using this definition of ICT (the ‘I’ is Information not Internet). Certainly, some form of connectivity is a defining characteristic of ICT but there have long been many ways to connect devices and, while internet protocols are the obvious choice for tech enterprises today, it is possible that other protocols will be more of a feature in future.
Regulation may itself be one of the factors determining future choices for connectivity protocols as we decide whether we want it to apply to particular kinds of service irrespective of how they connect or whether the intent is only to bring services using internet protocols into scope.
For example, video on demand services can be delivered over multiple different types of network, some IP based, and some proprietary. In the case of cable companies, these services are even delivered over the same physical wire into the premises and may appear on the same screens. When designing regulation for video services there are arguments that support either position of treating all services equally or of recognising differences between services tied to a proprietary infrastructure and those offered over the open internet.
At its most basic, this is about technological devices that can communicate with each other using networking protocols. So “tech” encompasses all of those interconnected devices as well as all of the equipment that carries the data that move between them.
But in the context of regulation we also want to include the people and organisations who own and direct those interconnected devices. So when we talk about “regulating tech” we often mean “regulating users of tech” as much as we do “regulating networks and devices”.
Devices that can operate autonomously of direction by a person may become a reality over time but more typically any device that connects with the internet is under the control of a “person”. It may be helpful to think of the definition of a “legal person” which includes both individuals and entities.
In some cases there will be a simple one-to-one relationship between a person and a physical device connected with the internet, eg an individual using a mobile phone. At the other extreme there may be a very complex set array of physical devices that sit behind a single logical node and the person controlling the node may be a very large corporation, eg the Google search engine run by Alphabet Inc. The principle is the same in both cases – there is a node that can connect with other nodes and it is under the control of an identifiable legal person.
To summarise – the world of “tech” I am considering as a candidate for regulation includes telecommunications networks, the nodes that connect with each other using those networks, and the people who control those nodes from individual users through to mega corporations. The networks and nodes I am focused on communicate using internet protocols today but it is the connectivity at scale that brings them into scope rather than the specific technology.
Let’s turn now to “regulation”.
Here, I mean the development and application of a set of rules to these networks, nodes and people. I am conscious that ‘regulated’ can be used to describe industries that are subject to specific sectoral regulatory frameworks. In most countries this applies to utility services like telecoms, water or power. I will dig into the different types of regulation in a later post but for now want to be clear that I mean all kinds of rules and degrees of control rather than just thinking of forms of sectoral regulation.
There are many different models for who “owns” rules and who enforces them. As I work through the specific areas of interest much of the debate will be precisely about perceived gaps between who currently owns and enforces rules and who should do this. The debate of our time is in large part about the extent to which the balance should shift from the tech sector developing and applying their own rules to governments doing this for (or to) them.
My starting point is to be ecumenical on these questions. There is no single ideal model for who should regulate tech (any more than there is for most other sectors) but rather there are options which each have their own strengths and weaknesses. If we can rigorously test different models and be honest about our real goals for regulation then we can make good policy choices. I will explore this in more depth in particular subject areas but my experience has shown me examples both of excessive belief that rules worked when they did not and of rules being imposed ostensibly for one purpose when the real motives were other.
Within that broad definition of developing and applying rules, I want to separate the problem out into different areas that may be regulated. As a sometime network engineer, I initially had in mind the layered stacks for the internet protocol suite and the OSI networking model.
These are elegant but were only designed to describe how communications work up to a technical “application” layer. Much of what interests us for regulation sits in what people have built on top of the network and is out of scope for documents about network protocols.
So I sketched out this model that more closely approximates with how I break down the areas of interest :-
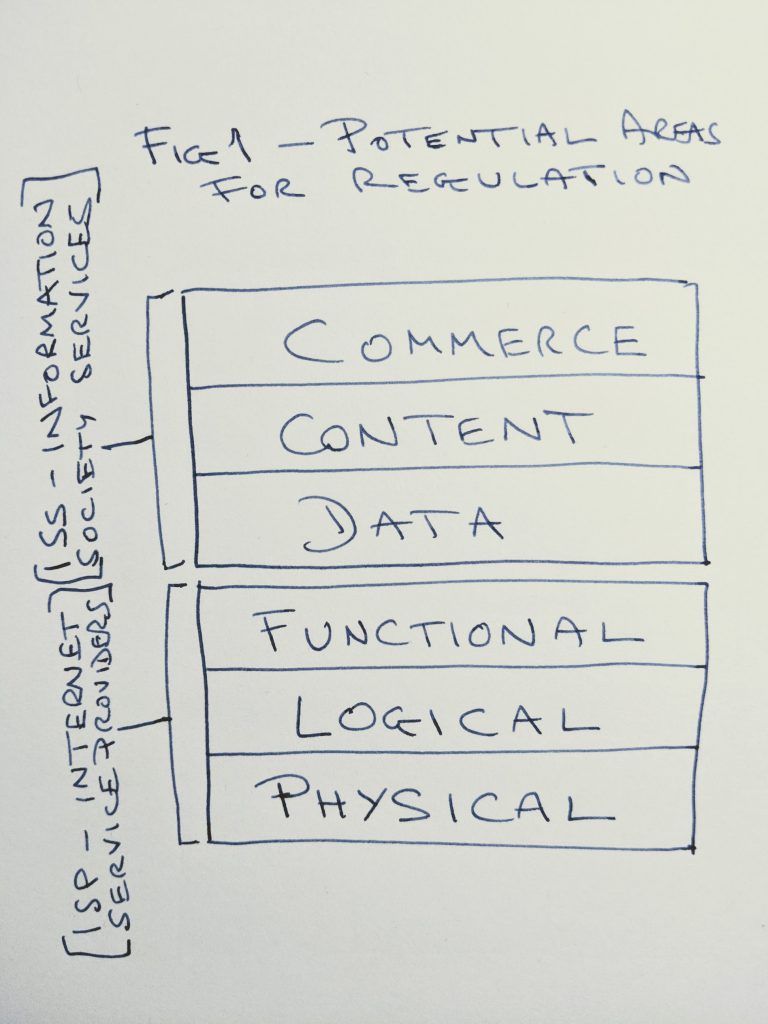
The bottom three layers provide the network infrastructure up to what may be called the ‘Application’ layer in the classic networking models. This means there are wires or wireless spectrum to send the electric signals over (Physical), an addressing scheme that means the signals get to the right machines (Logical), and shared protocols that make the signals useful (Functional).
For example, technical access to a website (packets routed via DNS and IP addresses to an HTTP server) or email service (sending and receiving mail using protocols like SMTP, IMAP and POP protocols from a server described in DNS) would be covered by these three layers.
I have placed three layers on top that do not necessarily stack up in this order but will frequently do so.
Activities across the network produce a certain amount of Data and will generally involve people sharing Content with each other. These activities could be across unmediated peer-to-peer connections but will more typically happen in the framework of some kind of legal entity set up to offer people a service as a form of Commerce.
I have used the terms “Internet Service Providers” and “Information Society Services” (usually referred to by their unlovely acronyms ISP and ISS) to describe the lower and upper halves of the stack. This is an attempt to try and create some order for my writing out of what is in reality a more messy picture.
The definition of ISP is in more common currency. These are the organisations, typically telecoms companies, who provide nodes with connections to the internet. We usually think of the consumer ISPs who provide a wired or wireless connection to most of us (generally for a fee) but ISPs also deliver backbone connectivity and other services to businesses that keep the packets flowing.
I have borrowed the term ISS from European Union legislation. It is not perfect but the nearest I could find for what I would like to include in the upper half of my stack.
“any service normally provided for remuneration, at a distance, by electronic means and at the individual request of a recipient of services. For the purposes of this definition:
(i) ‘at a distance’ means that the service is provided without the parties being simultaneously present;
(ii) ‘by electronic means’ means that the service is sent initially and received at its destination by means of electronic equipment for the processing (including digital compression) and storage of data, and entirely transmitted, conveyed and received by wire, by radio, by optical means or by other electromagnetic means;
(iii) ‘at the individual request of a recipient of services’ means that the service is provided through the transmission of data on individual request.”
DIRECTIVE (EU) 2015/1535 OF THE EUROPEAN PARLIAMENT AND OF THE COUNCIL
of 9 September 2015
The UK data protection regulator, the Information Commissioner’s Office, provides a helpful plain language interpretation of this the painful prose from the Directive –
Essentially this means that most online services are ISS, even if the ‘remuneration’ or funding of the service doesn’t come directly from the end user. For example an online gaming app or search engine that is provided free to the end user but funded via advertising still comes within the definition of an ISS.
It generally includes websites, apps, search engines, online marketplaces and online content services such as on-demand music, gaming and video services and downloads. It does not include traditional television or radio transmissions that are provided via general broadcast rather than at the request of an individual.
If you are uncertain whether your service is an ISS or not then we recommend you take your own legal advice, or refer to the following ‘further reading’ which provides more detailed clarification.
ICO Website – What are the rules about an ISS and consent?
The final comment to seek further legal advice reflects the fact that this definition is still being tested through litigation. Notably, Uber was found not to be an ISS by the European Court of Justice – a judgement that meant the Spanish authorities could apply other forms of taxi regulation to it.
I will explore some of these these questions about when a service should be regarded as inside the “tech” arena and when outside more in later posts. They are becoming very pertinent as “traditional” businesses expand their digital offers and as digital businesses compete on delivering physical goods and services.
I want to use examples of common user activities to try and bring this model and the questions facing policy makers and regulators to life. To close this first post, here is a simple example of what I mean with this model :-
Example 1 – Search Query
When I connect to the Google search engine from my mobile phone I am sending radio signals to a mast that will convert these into packets that run over a wired ‘backhaul’ network to an operator’s premises. My handset may come from a still quite diverse range of suppliers but the all-important operating system on it will most likely come from either Google or Apple.
The telecoms operator provides the Physical infrastructure and is responsible for implementing the Logical layer of Internet protocols so that my packets are routed correctly. I am using a Functional protocol – HTTP or HTTPS – that tells the network I intend to access a website. The ISP will connect me with the data centres run by Google, an Information Society Service (ISS).
The reality of how networks work today may mix this picture up a bit. For example, Google may have put caching servers into the operator’s network so that much of the transaction can take place entirely within the domain controlled by the Internet Service Provider (ISP). Or Google may be the provider of the entire stack as it offers its own access networks in some places.
Once I make the connection with Google then Data comes into play. There is some Data available to the ISP but this is quite limited and uninteresting if I am using an encrypted connection as is increasingly likely to be the case. My act of searching will generate some new Data for Google. The search interaction itself will also be dependent on the existing Data that Google holds both about the web as a whole and about me as an individual.
I produce Content in the form of my search terms and send this Content to Google. When it comes to search, Google then returns a small amount of Content from its indices to me. The substantive Content on the subject I am looking up belongs to the websites that Google points me towards rather than to Google itself. This distinction is an important one that certainly presents challenges for regulatory models as we will explore in later sections.
Google has created a business model where they have built a substantial Commerce layer around this modest exchange of Content – the few words in my search term and a few entries from their index. A search engine could create Commerce purely on the basis of advertising tied to the specific Content exchange but what happens in the Data layer can drive up the value of each interaction significantly. Today there may be dozens of entities capturing and processing Data to determine who gets to show their commercial Content alongside the search Content. This complexity has grown as available Data has grown and computing power has become cheaper.
Once the full set of Content has been generated it is sent back to my phone using the same network connection. In most cases, I will see the Content as intended and be quite unaware of the complexity and Data flows that led to its selection. If I am more active then I may use software on my device to change what I send in the first place, eg Do Not Track signals, or what I see when Content is returned, eg ad blockers. And I may try to gain some understanding of the Content I am seeing by looking into the advertising interest categories being applied to me or reading up on how search engine algorithms work.
In this single transaction, we already see many of the areas that are contentious for tech regulation. What requirements should regulation place on the lower half of the stack considering that the interests of Internet Service Providers and Information Society Services may not be aligned? How should all players be required to treat Data and should there be special rules for ISPs and ISSs or for different types of service or different kinds of data? Who should be responsible for each element of Content – search term, commercial content, search index and destination website – and what responsibility sits with the platform that pulls all this together? And plenty more!
Summary :- The ‘tech’ I have in mind for this project includes telecommunications networks, the nodes that connect with each other using those networks, and the people who control those nodes from individual users through to mega corporations. I think of ‘regulation’ as all possible sets of rules that may be applied to the sector. I propose a model to help analyse the different areas for potential regulation that has six layers – Physical, Logical, Functional, Data, Content and Commerce.